What's new at Rhino Health? (September 2024)

Chris Laws, Chief Operating Officer

Integrating and analyzing diverse datasets is crucial for advancing research and improving health outcomes. However, the sheer volume and variety of these data generated present significant challenges. This article explores the concept of data harmonization, its importance, and how Rhino Health’s Harmonization Copilot, integrated with the Rhino Federated Computing Platform (Rhino FCP), addresses these challenges. By automating the cleaning, standardization, and integration of varied datasets, the Harmonization Copilot enhances data quality, consistency, and interoperability, ultimately driving innovation and improving patient outcomes.
Data harmonization ensures that data from different sources are unified into a consistent format, enabling effective cross-institution patient care, medical research, and other collaborative efforts. Harmonization is a prerequisite for effectively generating large, high-quality datasets from multiple sources needed to train AI models. Without harmonization, data collected from various organizations—and sometimes from different countries—remains fragmented, leading to inconsistencies and potential errors in analysis and research findings. Data harmonization is a critical precursor to achieving interoperability across the participants in the healthcare ecosystem.
To fully grasp the concept of data harmonization, it’s helpful to distinguish it from related processes such as data standardization and data normalization:
The distinctions and importance of these processes are well-documented in scientific literature. For instance, Papez et al. (2023)¹ highlight the critical role of data harmonization in ensuring interoperability and facilitating large-scale analysis in their work on transforming the UK Biobank data to the OMOP² Common Data Model. Similarly, Wilkinson et al. (2016)³ emphasize the importance of standardizing data to adhere to the FAIR⁴ principles—Findable, Accessible, Interoperable, and Reusable. Data normalization principles, discussed in-depth by Codd (1970)⁵ in his pioneering work on the relational database model, remain fundamental to maintaining data integrity and reducing redundancy.
These processes—harmonization, standardization, and normalization—are interdependent and collectively ensure that data is high-quality, reliable, and ready for advanced analytical applications such as AI and machine learning. Harmonization is the most encompassing of the three, addressing the broader challenge of making diverse data sources compatible and comparable.
In the next section, we will explore the specific challenges of data harmonization and how the Harmonization Copilot effectively addresses these issues.
Data fragmentation is a pressing issue in healthcare, life sciences, and public health. The vast amount of data generated from various sources, such as clinical trials, patient records, laboratory tests, and genetic sequences, present both an opportunity and a challenge. Understanding these challenges is crucial for leveraging data effectively.
In the healthcare, life sciences, and public health sectors, data comes from various sources and formats, necessitating harmonization:
Data stored in local formats introduces friction in data collaborations, leading to inefficiencies and inaccuracies, compliance risks, and cost issues in research:
The following section will explore how Rhino Health’s Harmonization Copilot addresses these challenges and provides a comprehensive data integration and harmonization solution.
Data harmonization is crucial in ensuring that diverse datasets can be effectively used for advanced analytics and research. The Harmonization Copilot, an innovative application integrated with the Rhino FCP, addresses this need by automating the cleaning, standardization, and integration of varied datasets. This section provides an overview of the Harmonization Copilot, highlighting its key features and capabilities.
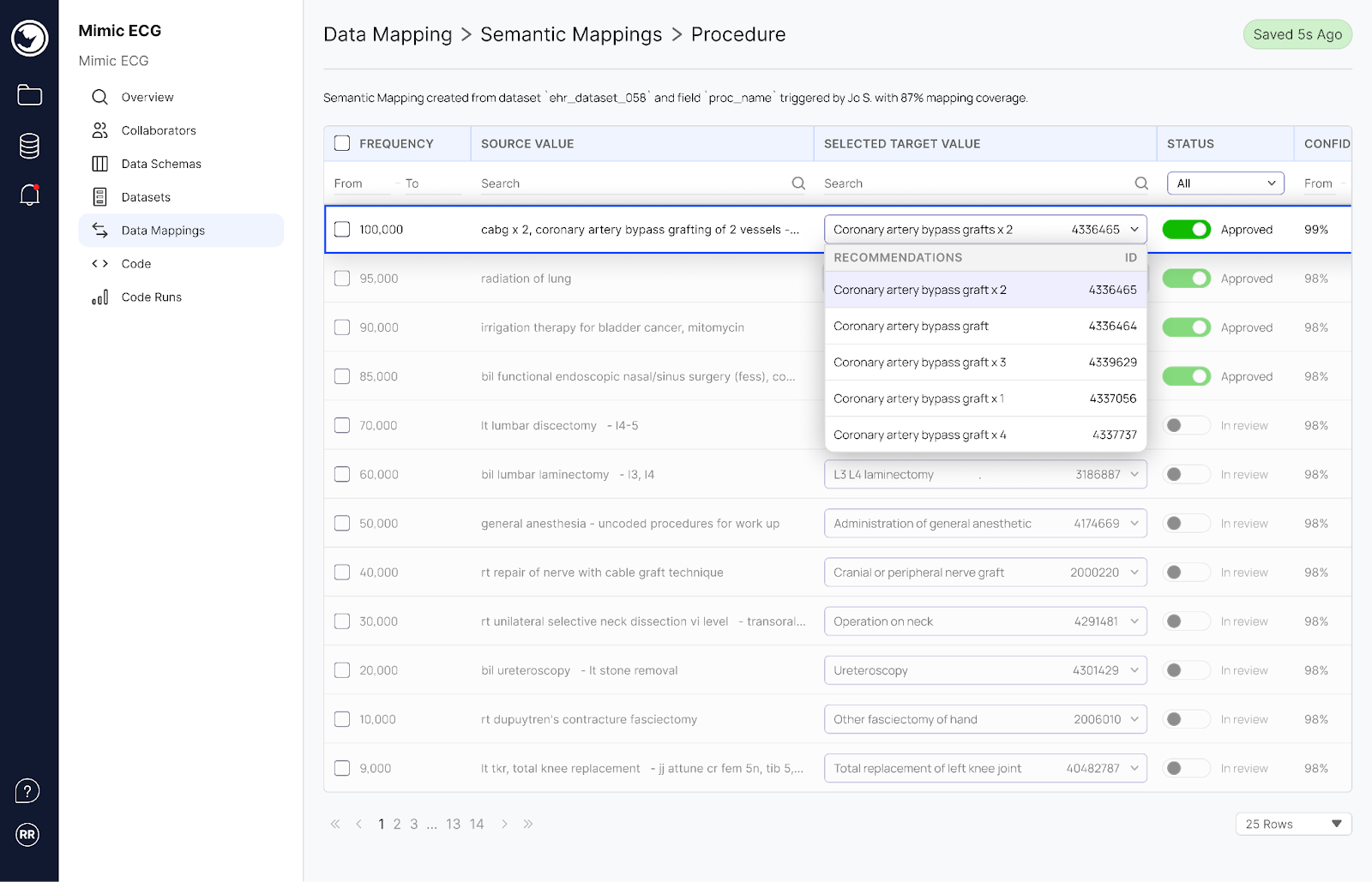
The Harmonization Copilot is designed to streamline data harmonization processes. It uses Generative AI⁸ to automate the labor-intensive tasks such as cleaning, standardizing, and integrating datasets from various sources, such as clinical trials, patient records, laboratory tests, and genetic sequences. Integration with Rhino FCP ensures a secure, scalable, and collaborative environment for data harmonization that does not require centralizing data to process it.
The Harmonization Copilot offers several key features and capabilities:
“Overseeing our partnership with Rhino Health has been transformative. The Harmonization Copilot has changed how we handle clinical data, seamlessly integrating and standardizing vast arrays of information across multiple systems. The Rhino Federated Computing Platform’s Harmonization Copilot not only enhances our operational efficiency but also boosts our capabilities in patient care and clinical research, strengthening our healthcare innovation assets at ARC Innovation at Sheba Medical Center.” —Benny Ben Lulu, Chief Digital Transformation Officer, Sheba Medical Center and Chief Technology Officer at ARC Innovation.
The Harmonization Copilot is designed to streamline and automate the data harmonization process, ensuring diverse datasets can be effectively integrated for advanced research and analysis.
Here is a step-by-step guide to how the Harmonization Copilot achieves this:
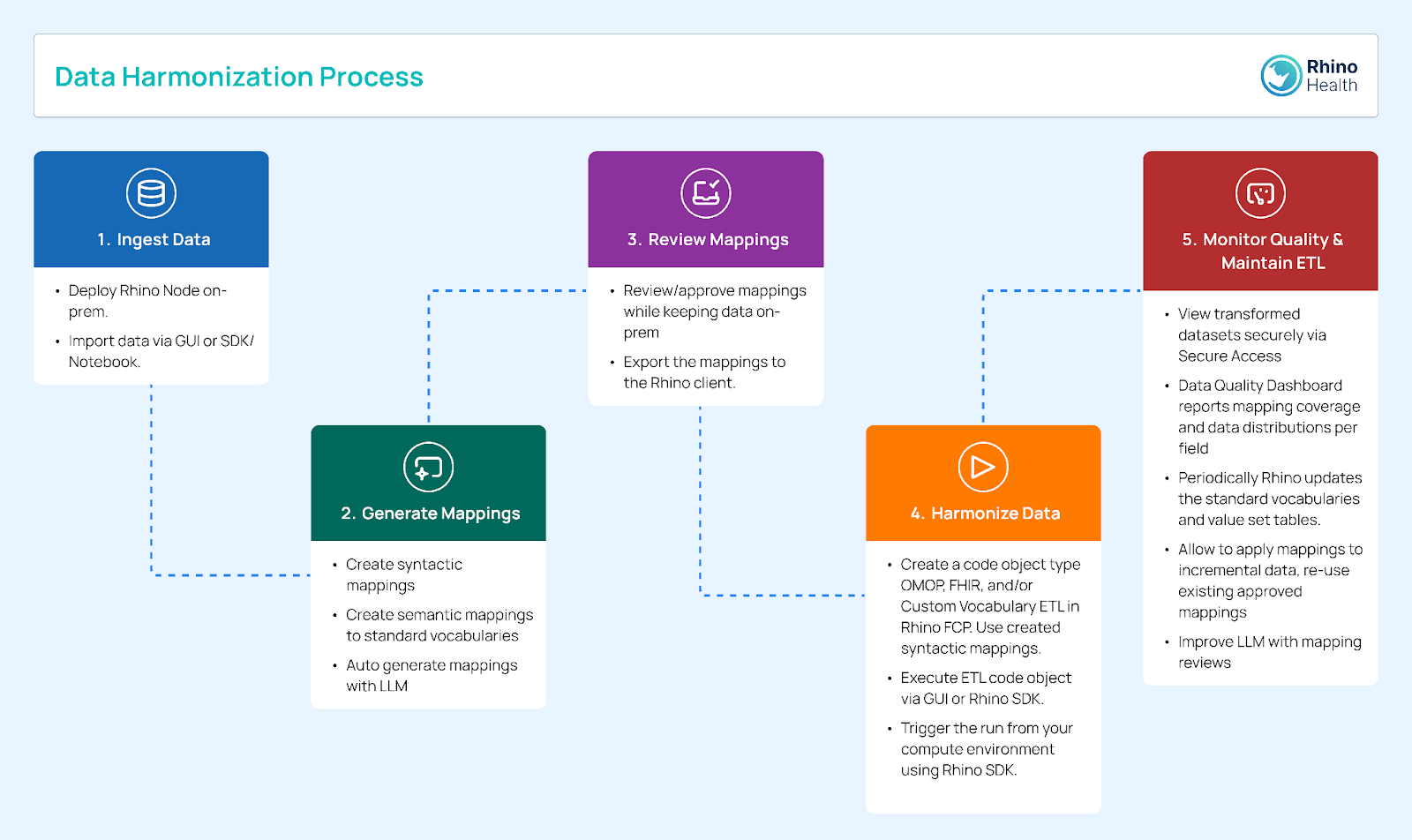
The Rhino FCP is a robust, cloud-based solution that facilitates collaborative data analysis while ensuring data privacy and regulatory compliance. It uses Federated Learning¹¹ and Edge Computing¹³ technologies, allowing multiple institutions to collaborate on data-driven projects without directly sharing sensitive data. This approach ensures data privacy and security, and facilitates compliance with regulations like GDPR and HIPAA.
Integrating the Harmonization Copilot with Rhino FCP significantly enhances data management by automating and streamlining the harmonization process at the edge. Keeping data within each organization’s secure infrastructure mitigates privacy risks and ensures compliance with regulations like HIPAA and GDPR. This decentralized method allows diverse datasets from various sources to be efficiently cleaned, standardized, and integrated without centralizing sensitive data. The Harmonization Copilot reduces manual effort and enables the creation of Federated Datasets, which can be used in collaborative research without sharing raw data.
The value chain from harmonized data to Federated Datasets to Federated Learning is transformative. Once data is harmonized at the edge, it can be used in Federated Learning, where machine learning models are trained across multiple institutions without moving the data. This ensures data privacy and enhances the robustness of the models by leveraging diverse datasets. Rhino FCP and the Harmonization Copilot support secure data access, quality monitoring, and controlled data sharing, fostering collaboration while maintaining complete control over data. This integrated approach drives innovation, improves research outcomes, and ensures transparent, compliant, and secure data processing across sectors.
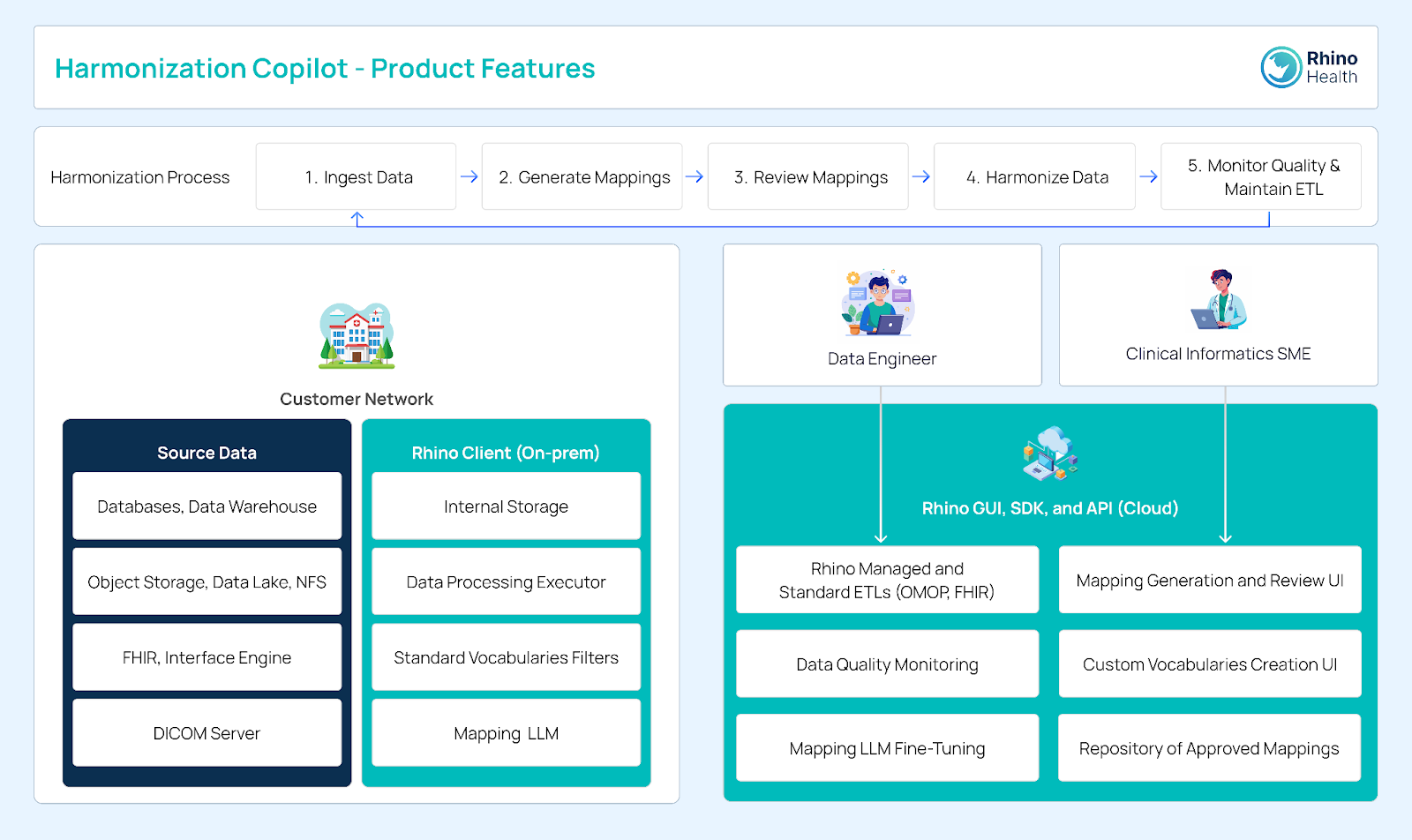
The Harmonization Copilot architecture includes the customer network with source data form databases, object storage, data lakes, FHIR interface engines and DICOM servers, alongside the Rhino Client (on-premises), which features internal storage, a data processing executor, standard vocabularies filters, and a mapping LLM.
Data engineers and clinical data SMEs access the Harmonization Copilot via the Rhino GUI. which includes managed and standard ETLs, data quality monitoring, mapping LLM fine-tuning, mapping generation and review, custom vocabularies creation, and a repository of approved mappings.
The Harmonization Copilot architecture integrates on-premises data sources with processing tools ensuring data privacy and security while facilitating efficient harmonization. It enables organizations to leverage their data for AI and machine learning applications, driving innovation and improving patient outcomes in the healthcare, life sciences, and public health sectors.
The Harmonization Copilot, integrated with the Rhino FCP, addresses the data harmonization challenges in the healthcare, life sciences, and public health sectors.
Data Harmonization is vital for transforming diverse datasets into a cohesive format, essential for advanced analytics and research in the healthcare, life sciences, and public health sectors. The Harmonization Copilot offers substantial benefits by automating data cleaning, standardization, and integration improving data quality, consistency, and interoperability. Unlike standardization (consistent formats) and normalization (reducing redundancy), harmonization ensures compatibility across diverse data sources.
The Rhino Federated Computing Platform’s Harmonization Copilot application significantly reduces the manual effort required for data preparation, enabling researchers to focus on high-value tasks like data interpretation and hypothesis generation. The Harmonization Copilot is invaluable for any organization dealing with complex data by enhancing research efficiency, accelerating drug development, and improving patient outcomes.
Dive into our in-depth articles, “Transforming Public Health Practice with Rhino Health’s Harmonization Copilot” and “Transforming Life Science Data with Rhino Health’s Harmonization Copilot,” to see how this technology is making an impact in the real world. To experience the capabilities of the Harmonization Copilot firsthand, schedule a demo with our team.
References and Notes:
¹ Papez, V., Denaxas, S., Hemingway, H., et al. (2023). Transforming and evaluating the UK Biobank to the OMOP Common Data Model for COVID-19 research and beyond. Oxford Academic | JAMIA A Scholarly Journal of Informatics in Health and Biomedicine. Available at: https://academic.oup.com/jamia/article/30/1/103/6760234. Accessed: 27 June 2024.
² OMOP (Observational Medical Outcomes Partnership): A standardized data model to facilitate large-scale analytics across diverse healthcare databases.
³ Wilkinson, M.D., Dumontier, M., Aalbersberg, I.J., et al. (2016). The FAIR Guiding Principles for scientific data management and stewardship. Scientific data, 3(1), pp.1-9. Available at: https://www.nature.com/articles/sdata201618. Accessed 27 June 2024.
⁴ FAIR Principles: Guidelines to improve the Findability, Accessibility, Interoperability, and Reusability of digital assets, ensuring data is discoverable, accessible, compatible, and reusable for future research.
⁵ Codd, E.F. (1970). A Relational Model of Data for Large Shared Data Banks. Communications of the ACM, 13(6), pp.377-387. Available at: https://dl.acm.org/doi/10.1145/362384.362685. Accessed 27 June 2024.
⁶ HIPAA (Health Insurance Portability and Accountability Act): A US law designed to provide privacy standards to protect patients’ medical records and other health information.
⁷ GDPR (General Data Protection Regulation): A regulation in EU law on data protection and privacy in the European Union and the European Economic area.
⁸ LLMs (Large Language Models): A type of AI model capable of understanding and generating human-like text based on large datasets.
⁹ FHIR (Fast Healthcare Interoperability Resources): A standard describing data formats and elements (known as “resources”) and an application programming interface for exchanging electronic health records.
¹⁰ ETL (Extract, Transform, Load): A database usage and data warehousing process responsible for pulling data out of the source systems and placing it into a data warehouse.
¹¹ Federated Learning: Federated Learning is a decentralized machine learning approach enabling multiple institutions to train AI models collaboratively without sharing raw data. This method ensures data privacy and security by keeping data within local environments and only sharing model updates. A prominent example of its application is the EXAM model¹² developed for predicting COVID-19 clinical outcomes, which utilized data from 20 institutes globally without direct data sharing. This model demonstrated significant improvements in predicting performance and generalizability across diverse datasets, showcasing the potential of Federated Learning in healthcare.
¹² Dayan, I., Roth, H. R., Zhong, A., et al. (2021). Federated Learning for Predicting Clinical Outcomes in Patients with COVID-19. Nature Medicine. Available at: https://www.nature.com/articles/s41591-021-01506-3. Accessed 2 July 2024. Dr. Ittai Dayan is the Co-founder and CEO of Rhino Health.
¹³ Edge Computing: A distributed computing paradigm that brings computation and data storage closer to the data sources. This approach reduces latency, enhances data security, and improves response times by processing data locally on devices or edge servers rather than relying on a centralized cloud infrastructure. Edge Computing is essential for real-time processing and is particularly beneficial in scenarios where data privacy and quick decision-making are critical.





